Do Not Forget to Attend to Uncertainty while Mitigating Catastrophic Forgetting
Vinod Kumar Kurmi , Badri N Patro, Venkatesh K Subramanian, Vinay P. Namboodiri
Indian Institute of Technology Kanpur
[Paper] [ArXiv] [Code] [Poster]
Abstract
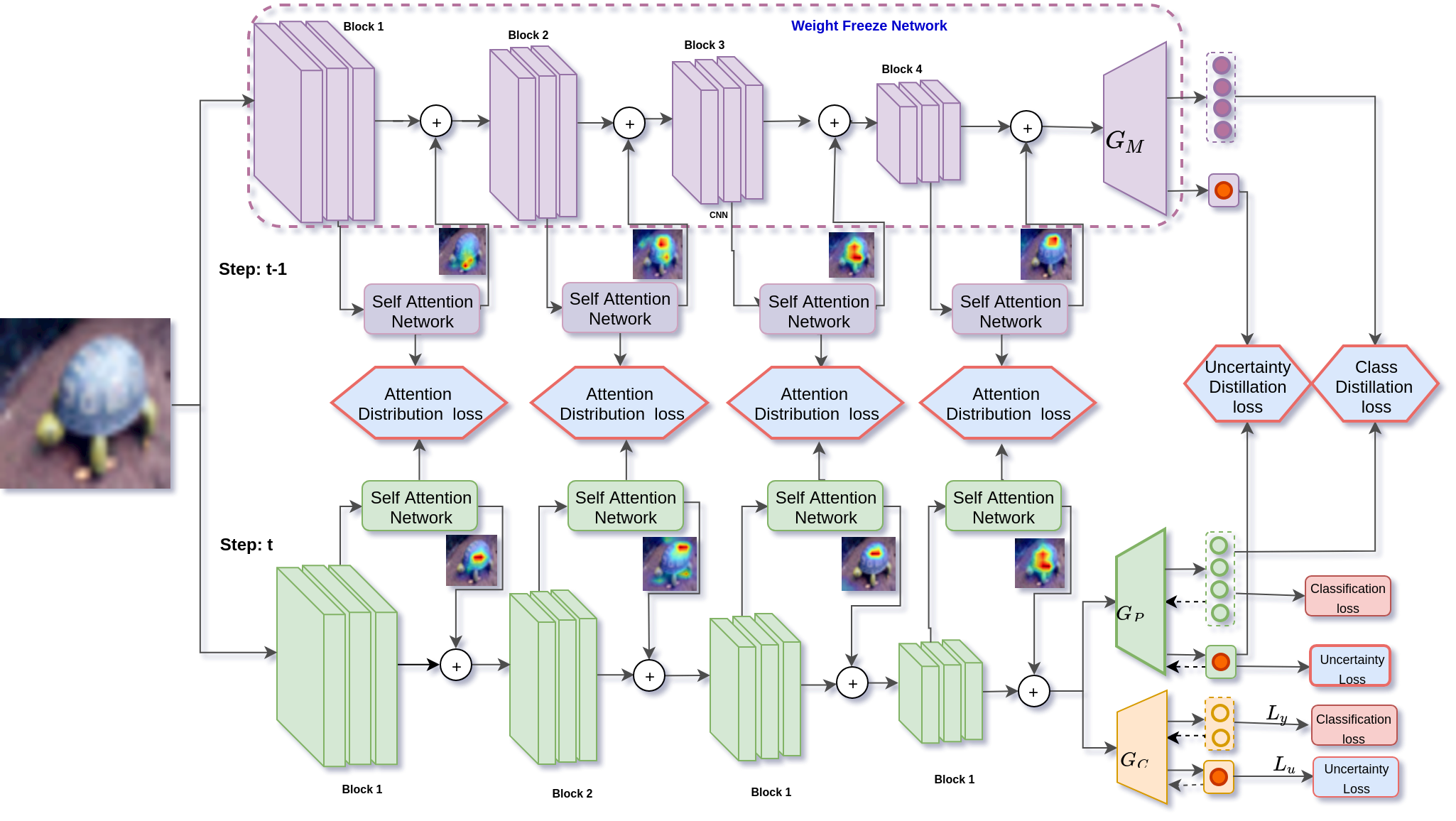
One of the major limitations of deep learning models is that they face catastrophic forgetting in an incremental learning scenario. There have been several approaches proposed to tackle the problem of incremental learning. Most of these methods are based on knowledge distillation and do not adequately utilize the information provided by older task models, such as uncertainty estimation in predictions. The predictive uncertainty provides the distributional information can be applied to mitigate catastrophic forgetting in a deep learning framework. In the proposed work, we consider a Bayesian formulation to obtain the data and model uncertainties. We also incorporate self-attention framework to address the incremental learning problem. We define distillation losses in terms of aleatoric uncertainty and self-attention. In the proposed work, we investigate different ablation analyses on these losses. Furthermore, we are able to obtain better results in terms of accuracy on standard benchmarks.
Code Coming Soon!
 |
V. K. Kurmi, B.N. Patro, Venkatesh KS, V. P. Namboodiri Do Not Forget to Attend to Uncertainty while Mitigating Catastrophic Forgetting |
BibTex
@InProceedings{Kurmi_2021_wacv,
author = {Kumar Kurmi, Vinod and N Patro, Badri and K Subramanian,Venkatesh and Namboodiri, Vinay P.},
title = {Do Not Forget to Attend to Uncertainty while Mitigating Catastrophic Forgetting},
booktitle = {IEEE WACV,},
year = {2021}
}