
U-CAM: Visual Explanation using Uncertainty based Class Activation Maps
Badri N. Patro, Mayank Lunayach, Shivansh Patel, Vinay P. Namboodiri

Abstract:
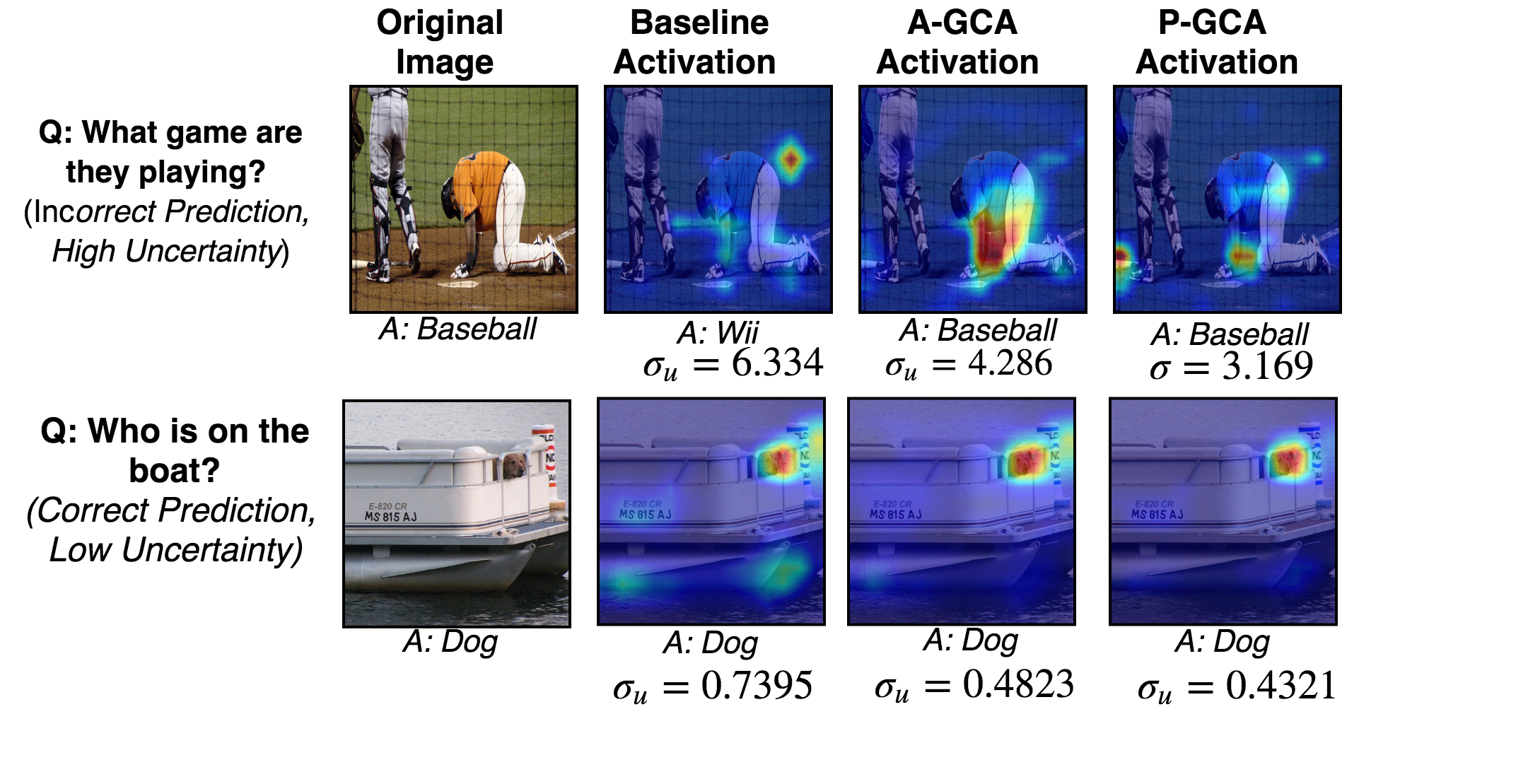
The figure shows the activation maps for baseline and our models (A-GCA and P-GCA). In the first exaample, the baseline model had predicted the wrong answer and had high uncertainty in prediction. Our model gave a correct answer while also minimizing the uncertainty (thus leading to an improved visual explanation).
Understanding and explaining deep learning models is an imperative task. Towards this, we propose a method that obtains gradient-based certainty estimates that also provide visual attention maps. Particularly, we solve for visual question answering (VQA) task. We incorporate modern probabilistic deep learning methods that we further improve by using the gradients for these estimates. These have two-fold benefits:
- Improvement in obtaining the certainty estimates that correlate better with misclassified samples.
- Improved attention maps that provide state-of-the-art results in terms of correlation with human attention regions.
The improved attention maps result in consistent improvement for various methods for visual question answering. Therefore, the proposed technique can be thought of as a recipe for obtaining improved certainty estimates and explanation for deep learning models. We provide detailed empirical analysis for the visual question answering task on all standard benchmarks and comparison with state of the art methods.

The first column is the original image. 2nd, 3rd, 4th, and 5th columns represent the baseline attention, attention when only image uncertainty was minimized, attention when only question uncertainty was minimized, attention when both image and question uncertainties were minimized (our proposed model) respectively.
U-CAM Model:
Illustration of model Gradient-based Certainty Attention Mask (GCA) and its certainty mask. We obtain image feature and question feature using CNN and LSTM, respectively. We then obtain attention mask using these features, and classification of the answer is done based on the attended feature.
Some example of visual explanations using our method:
|
|
||||||||




|
|
||||||||




|
|
||||||||




Cite us
title={U-CAM: Visual Explanation using Uncertainty based Class Activation Maps},
author={Badri N. Patro and Mayank Lunayach and Shivansh Patel and Vinay P. Namboodiri},
booktitle={arXiv preprint arXiv:1908.06306},
year={2019}}